
SVK
Article publié dans Linux Magazine 94, mai 2007.
Copyright © 2007 – Nicolas Chuche
- Index
- Introduction
- Installation
- Utilisation simple
- Utilisation avancée
- Éléments de méthode de travail
- SVK version 2
- Quelques idées en l’air
- Conclusion
- Les liens
- Ours
Chapeau de l’article
Cet article est un tutoriel pour le logiciel de gestion de versions SVK, qui est parti du constat que, ayant besoin de SVK et ne le connaissant pas bien, le meilleur moyen de le maîtriser était d’approfondir mes connaissances et de les organiser dans un tutoriel à destination d’un public le plus large possible.
Installation
L’installation de SVK est d’une simplicité légendaire s’il est disponible sous forme de paquets :
|
1 2 |
<a name="h2"> % sudo aptitude install svk # Debian et dérivées % sudo urpmi svk # Mandriva</a> |
Sous Windows il existe un portage trouvable ici http://home.comcast.net/~klight/svk/
Si aucun paquet de SVK n’existe pour votre distribution, vous allez devoir passer par un shell d’installation Perl, CPAN ou CPANPLUS.
|
1 2 |
% sudo cpan SVK # avec CPAN.pm % cpanp i SVK # avec CPANPLUS |
Comme me le souffle un camarade, une installation « à la main » n’est pas des plus simples car il vous faudra installer ou compiler un Subversion avec les bindings Perl. Vous pourrez trouver de l’aide sur le wiki de SVK : http://svk.bestpractical.com/view/InstallingSVK.
Utilisation simple
Création d’un dépôt local
La première étape est de créer un dépôt sur votre machine :
|
1 2 |
<a name="h3.1"> % svk depotmap --init Repository /home/test/.svk/local does not exist, create? (y/n)y</a> |
|
1 2 |
<a name="h3.1"> % svk mkdir //local/ -m 'creation du repertoire local' Committed revision 1.</a> |
Travailler sur un projet déjà dans un dépôt
La syntaxe normale pour récupérer les fichiers d’un dépôt centralisé est :
|
1 |
<a name="h3.2"> % svk checkout protocole://le.serveur.net/le/chemin/mon/appli repertoire</a> |
Quand vous allez taper cette commande pour la première fois, svk va vous poser trois questions :
|
1 2 3 4 5 6 |
<a name="h3.2"> % svk mirror --list Path Source ============================================================ //mirror/mesprojets https://mon.serveur.com/svn //mirror/mongueurs svn+ssh://autre.serveur.com/home/nc/.svk/local/local/mongueurs/trunk</a> |
Voyons maintenant un exemple (pour redmine, voir dans les références à la fin de cet article) :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<a name="h3.2"> % svk checkout svn://rubyforge.org/var/svn/redmine/ New URI encountered: svn://rubyforge.org/var/svn/redmine/ Choose a base URI to mirror from (press enter to use the full URI): [...] Depot path: [//mirror/redmine] [...] a)ll, h)ead, -count, revision? [a] Syncing svn://rubyforge.org/var/svn/redmine Retrieving log information from 1 to 21 Committed revision 10297 from revision 1. [...] Syncing //mirror/redmine(/mirror/redmine) in /home/nc/tmp/redmine to 10317.</a> |
|
1 2 3 |
<a name="h3.2"> % svk checkout svn://rubyforge.org/var/svn/redmine/trunk redmine % svk checkout https://rubyforge.org/var/svn/redmine/trunk redmine</a> |
Ou encore si vous avez accès au dépôt par ssh :
|
1 |
<a name="h3.2"> % svk checkout svn+ssh://rubyforge.org/var/svn/redmine/trunk redmine</a> |
Créer un nouveau projet à partir de fichiers existants
Vous avez déjà un répertoire que vous souhaitez gérer avec SVK. La commande à utiliser est import :
|
1 |
<a name="h3.3"> % svk import --message 'import initial' monprojet/ //local/monprojet</a> |
|
1 2 3 |
<a name="h3.3"> monprojet/branches/ tags/ trunk/<tous vos fichiers et répertoires></a> |
|
1 |
<a name="h3.3"> % svk checkout //local/monprojet/trunk monprojet</a> |
|
1 |
<a name="h3.3"> % svk import --message 'import initial' -t monprojet/ //local/monprojet</a> |
Travailler sur votre projet
Plusieurs commandes vous seront utiles :
- svk diff
Vous donne un
diffentre la version d’origine du dépôt et votre copie de travail. Cette commande peut prendre en argument un ou plusieurs fichiers/répertoires, vous ne verrez alors que leurs différences. - svk add
Ajoute des fichiers ou des répertoires dans le dépôt
Les fichiers ne seront réellement ajoutés qu’au prochain commit (cf point suivant).
1234% svk add repA repA rep/aA rep/bCette commande est récursive, si vous ajoutez un répertoire, tous les fichiers contenus seront également ajoutés.
Vous pouvez ajouter tous les nouveaux répertoires et fichiers d’un seul coup en faisant :
1% svk add .Un point intéressant à savoir,
svkest (plus ou moins) intelligent, il n’ajoutera pas les fichiers de finissant par un « ~ » ainsi qu’un certain nombre d’autres motifs. La liste complète par défaut est :*.o *.lo *.la #*# .*.rej *.rej .*~ *~ .#* .DS_Store - svk commit
Permet d’enregistrer vos modifications dans le dépôt. Cette commande prend en option un commentaire, ce commentaire sert à décrire la ou les modifications apportées.
12% svk ci -m 'quelques modifications'Committed revision 3.Je vous suggère (fortement) d’être le plus précis possible dans les messages que vous associez aux commits. Cela vous permettra d’avoir une trace fiable.
Définition : révision
Cela fait déjà quelques fois que nous rencontrons ce terme de « révision » dans les sorties écran de
svk. À chaque fois que vous faites un commit (ou une opération faisant un commit sans vous le dire comme par exemplepullousmergeque nous verrons plus tard),svkva créer dans le dépôt un nouvel état du système de fichier contenant toutes vos modifications, ces états sont appelés des révisions. - svk delete
Permet de supprimer un fichier dans le dépôt. Supprimer un fichier sur votre système de fichier n’avertit pas
svk, cette commande lui précise que ce fichier n’existe plus. Dans le dépôt,svkne supprime pas réellement le fichier, il garde bien sûr une trace de toutes les modifications qui y ont été apportées. Vous pourrez donc retrouver toutes ses versions si besoin est. - svk rename
Permet de renommer un fichier ou un répertoire. Si vous déplacez le fichier par les commandes liées à votre OS,
svkne pourra pas le savoir. Vous devez utiliser cette commande :1% svk rename config/ etc/Comme
addetdelete, cette commande ne prend effet réellement qu’après le prochain commit. - svk revert
Permet de « défaire » les éditions locales. Si vous avez modifié un fichier ou bien exécuté une commande
addoudeletepar exemple mais que vous n’avez pas encore commité, vous pouvez revenir à l’état d’avant ceaddou cedelete:123456789101112131415% svk status# on crée un nouveau fichier% touch yyyyy# ce fichier est marqué comme inconnu par svk% svk status? yyyyy# on l'ajoute par svk, il le marque comme à ajouter% svk add yyyyyA yyyyy# on le 'revert'% svk revert yyyyyReverted yyyyy# il est à nouveau marqué comme inconnu% svk status? yyyyy - svk status
Vous permet de voir rapidement l’état de vos fichiers
12345% svk statusM a.c! a.h? b.c? b.hLe
Mindique que le fichier a été modifié, le!que le fichier n’existe plus dans les fichiers locaux et le?que le fichier n’existe pas dans le dépôt. Pour une liste complète, référez vous au SVK Book.
Mettre à jour les fichiers locaux à partir du dépôt
|
1 |
<a name="h3.5"> % svk update</a> |
|
1 2 3 4 5 |
<a name="h3.5"> % svk update Syncing //local/monprojet/trunk(/local/monprojet/trunk) in /home/test/monprojet to 6. Conflict found in a.c: e)dit, d)iff, m)erge, s)kip, t)heirs, y)ours, h)elp? [e]</a> |
svk s’est rendu compte du problème et vous propose plusieurs choix. Dans l’immédiat nous n’allons utiliser qu’une des options (je vous laisse découvrir les autres), à savoir l’option "s". Cette dernière intègre les modifications apportées par les co-éditeurs du fichiers. À vous de rêgler le conflit :
|
1 2 3 4 5 6 7 8 |
<a name="h3.5"> % cat a.c >>>> YOUR VERSION a.c 115722413378427 #include "d.h" ==== ORIGINAL VERSION a.c 115722413378427 #include "b.h" ==== THEIR VERSION a.c 115722413378427 #include "e.h" <<<< 115722413378427</a> |
Après avoir résolu le conflit, vous devrez prévenir svk avec :
|
1 |
<a name="h3.5"> % svk resolved a.c</a> |
Et ensuite vous pourrez commiter cette modification afin de ne pas laisser traîner le conflit :
|
1 |
<a name="h3.5"> % svk commit a.c</a> |
Regarder l’historique des modifications
Pour voir toutes les actions réalisées, vous pouvez faire svk log.
svk cat permet de voir l’état d’un fichier dans le dépôt. Nous verrons un peu plus loin un argument idéal à utiliser avec cette commande.
Quelques autres commandes
Voici quelques autres commandes qui pourront vous être utiles au cours de votre utilisation de svk :
-
1<a name="h3.7"> % svk checkout --export //local/redmine/trunk redmine</a>
-
123456<a name="h3.7"> % svk list //mirrorarticles/monprojet/mongueurs/redmine/tracks/</a>
-
12<a name="h3.7"> % svk mkdir monrepertoire% svk mkdir //local/quelquechose</a>
-
12345678910111213<a name="h3.7"> % svk infoCheckout Path: /home/nc/travail/rails/redmineDepot Path: //local/redmine/trunk/redmineRevision: 10389Last Changed Rev.: 10389Copied From: /mirror/redmine/trunk/redmine, Rev. 10375Merged From: /mirror/redmine/trunk/redmine, Rev. 10388% svk info //mirror/redmineDepot Path: //mirror/redmineRevision: 10410Last Changed Rev.: 10388Mirrored From: svn://rubyforge.org/var/svn/redmine, Rev. 22</a>
Quelques options bien utiles
|
1 2 3 4 5 6 7 |
<a name="h3.8"> % svk diff -r {2006-07-09}:{2006-07-10} === redmine/app/helpers/search_filter_helper.rb ================================================================== --- redmine/app/helpers/search_filter_helper.rb (revision 10337) +++ redmine/app/helpers/search_filter_helper.rb (revision 10340) @@ -29,10 +29,12 @@ end</a> |
Pour préciser que vous voulez comparer par rapport à la dernière version utilisez HEAD :
|
1 |
<a name="h3.8"> % svk diff -r {2006-07-09}:HEAD</a> |
|
1 |
<a name="h3.8"> % svk cat -r {2006-07-09} redmine/app/helpers/search_filter_helper.rb</a> |
checkout et update acceptent également un argument -r qui permet de préciser à partir de quelle révision on veut se mettre à jour.
|
1 2 3 4 5 6 7 8 9 |
<a name="h3.8"> % svk checkout --list Depot Path Path ======================================================================== //local/mesprojets/bbrails/trunk /home/nc/travail/rails/bbrails //local/mesprojets/fpw2006 /home/nc/travail/rails/fpw2006 //local/mesprojets/gestapp/trunk /home/nc/travail/rails/gestapp //local/mongueurs/trunk /home/nc/travail/mongueurs //local/redmine/trunk/redmine /home/nc/travail/rails/redmine ? //local/mesprojets/test /home/nc/tmp/prosper</a> |
|
1 2 3 4 5 |
<a name="h3.8"> % svk checkout --purge Purge checkout of //local/mesprojets/test to non-existing directory /home/nc/tmp/prosper? (y/n) y Checkout path '/home/nc/tmp/prosper' detached.</a> |
Utilisation avancée
Les branches et les tags
|
1 2 3 |
<a name="h4.1"> branches/ - les différentes versions de développement tags/ - des images figées trunk/ - la dernière version en cours de développement</a> |
Création de branches et de tags
La commande utilisée pour créer des tags et des branches est la même, il s’agit de svk copy :
|
1 2 3 4 |
<a name="h4.1.1"> % svk copy //local/monprojet/trunk \ //local/monprojet/branches/monprojet-1.0 \ -m 'creation de la branches 1.0' Committed revision 5.</a> |
|
1 2 |
<a name="h4.1.1"> % svk list //local/monprojet/branches/ monprojet-1.0/</a> |
|
1 2 3 |
<a name="h4.1.1"> % svk copy //local/monprojet/branches/monprojet-1.0 \ //local/monprojet/tags/monprojet-1.0 -m 'version 1.0 diffusée' Committed revision 7.</a> |
Passer votre copie de travail d’une branche à une autre
|
1 |
<a name="h4.1.2"> % svk switch //local/monprojet/branches/monprojet-1.0/</a> |
Pour repasser dans trunk il suffit de faire :
|
1 |
<a name="h4.1.2"> % svk switch //local/monprojet/trunk/</a> |
La fusion
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<a name="h4.1.3"> % svk smerge -Il //local/monprojet/branches/monprojet-1.0 \ //local/monprojet/trunk Auto-merging (0, 8) /local/monprojet/branches/monprojet-1.0 to /local/monprojet/trunk (base /local/monprojet/trunk:4). ===> Auto-merging (0, 5) /local/monprojet/branches/monprojet-1.0 to /local/monprojet/trunk (base /local/monprojet/trunk:4). Empty merge. ===> Auto-merging (5, 8) /local/monprojet/branches/monprojet-1.0 to /local/monprojet/trunk (base /local/monprojet/trunk:4). U db/migrate/001_setup.rb New merge ticket: 0aca4fd4-bb1c-0410-adf5-ecdeea5a58f8: /local/monprojet/branches/monprojet-1.0:8 Committed revision 9.</a> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<a name="h4.1.3"> % svk smerge -Il //local/monprojet/branches/monprojet-1.0 \ //local/monprojet/trunk Auto-merging (8, 11) /local/monprojet/branches/monprojet-1.0 to /local/monprojet/trunk (base /local/monprojet/branches/monprojet-1.0:8). ===> Auto-merging (8, 11) /local/monprojet/branches/monprojet-1.0 to /local/monprojet/trunk (base /local/monprojet/branches/monprojet-1.0:8). Conflict found in config/config_custom.rb: e)dit, d)iff, m)erge, s)kip, t)heirs, y)ours, h)elp? [e] e Waiting for editor... Merged config/config_custom.rb: a)ccept, e)dit, d)iff, m)erge, s)kip, t)heirs, y)ours, h)elp? [a] a G config/config_custom.rb New merge ticket: 0aca4fd4-bb1c-0410-adf5-ecdeea5a58f8: /local/monprojet/branches/monprojet-1.0:11 Committed revision 12.</a> |
|
1 2 |
<a name="h4.1.3"> % svk smerge -Il //local/monprojet/branches/monprojet-1.0 \ /ma/copie/de/travail</a> |
Fusionner seulement quelques révisions
Aussi parfois appelé « cherry picking » (cueillette de cerise).
smerge ne sait pas faire ça, il va falloir se rabattre sur la commande merge.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<a name="h4.1.4"> % svk log ---------------------------------------------------------------------- r16: test | 2006-09-06 15:23:04 +0200 ajout d'une fonctionnalite pour la v2.0 ---------------------------------------------------------------------- r15: test | 2006-09-06 15:22:32 +0200 correction bug bloquant ---------------------------------------------------------------------- r14: test | 2006-09-06 15:22:14 +0200 ajout d'une fonctionnalite pour la v2.0</a> |
|
1 2 3 4 5 6 7 8 9 10 11 |
<a name="h4.1.4"> % svk diff -r 14:15 //local/monlogiciel/trunk/ === generate ================================================================== --- generate (revision 14) +++ generate (revision 15) @@ -1,4 +1,4 @@ #!/usr/bin/env ruby # commentaire -requir File.dirname(__FILE__) + '/../config/boot' +require File.dirname(__FILE__) + '/../config/boot' require 'commands/generate'</a> |
|
1 2 |
<a name="h4.1.4"> % svk merge -r 14:15 //local/monlogiciel/trunk/ U generate</a> |
Il vous faudra alors commiter ces modifications.
Gérer des modifications locales dans un logiciel
-
Créez une arborescence standard branches/tags/trunk
1<a name="h4.1.5"> mkdir -p monlogiciel/{branches,tags,trunk}</a> -
Récupérez une archive de votre logiciel et décompactez-la directement dans trunk.
-
faites un import de toute l’arborescence
12<a name="h4.1.5"> % svk import -m "premier import de monlogiciel" monlogiciel \//local/monlogiciel</a> -
faites une copie de trunk vers une branche sur laquelle vous ferez vos modifications :
12<a name="h4.1.5"> % svk copy -m "creation de la copie locale" //local/monlogiciel/trunk \//local/monlogiciel/branches/monlogiciel-local</a> -
Une nouvelle version de monlogiciel est sortie, récupérez-la à nouveau et décompactez-la.
12<a name="h4.1.5"> % svk import -m "import de monlogiciel v1.2" monlogiciel \//local/monlogiciel/trunk</a> -
Essayez de fusionner le nouveau trunk avec votre version locale :
12345678<a name="h4.1.5"> % svk smerge -C //local/monlogiciel/trunk \//local/monlogiciel/branches/monlogiciel-localAuto-merging (2, 5) /local/monlogiciel/trunk to/local/monlogiciel/branches/monlogiciel-local(base /local/monlogiciel/trunk:2).U consoleNew merge ticket: 6d4c1533-f1fa-4670-b606-7b3ba989afbe:/local/monlogiciel/trunk:5</a>123456789101112<a name="h4.1.5"> % svk smerge -Il //local/monlogiciel/trunk \//local/monlogiciel/branches/monlogiciel-localAuto-merging (2, 5) /local/monlogiciel/trunk to/local/monlogiciel/branches/monlogiciel-local (base/local/monlogiciel/trunk:2).===> Auto-merging (2, 5) /local/monlogiciel/trunk to/local/monlogiciel/branches/monlogiciel-local (base/local/monlogiciel/trunk:2).U consoleNew merge ticket: 6d4c1533-f1fa-4670-b606-7b3ba989afbe:/local/monlogiciel/trunk:5Committed revision 6.</a> -
Recommencez la procédure ci-dessus ad-nauseam à chaque nouvelle version de votre logiciel.
Travailler en mode déconnecté
|
1 2 3 4 5 6 |
<a name="h4.2"> projet/a.c /a.c-version_de_debuggage /a.c-1 /a.c-2 /a.c-bug_machin /...</a> |
Cela devient vite horrible et inutilisable (bien que des gens utilisent encore cette méthode).
|
1 2 |
<a name="h4.2"> % svk mirror https://rubyforge.org/var/svn/redmine/ //mirror/redmine % svk sync //mirror/redmine</a> |
Une fois cette étape réalisée, vous allez faire une copie locale des données récupérées :
|
1 |
<a name="h4.2"> % svk copy //mirror/redmine //local/redmine</a> |
|
1 |
<a name="h4.2"> % svk pull</a> |
|
1 |
<a name="h4.2"> % svk push</a> |
|
1 |
<a name="h4.2"> % svk diff //mirror/monprojet/ //local/monprojet/</a> |
Proposer des modifications quand vous n’avez pas les droits d’écriture sur le dépôt
|
1 2 3 4 5 6 |
<a name="h4.3"> % svk push --patch svk_correction_bug Auto-merging (10574, 10606) /local/mongueurs/trunk to /mirror/mongueurs/trunk (base /mirror/mongueurs/trunk:10604). Patching locally against mirror source svn://svn.mongueurs.net/articles. U magazines/Applications/svk.pod Patch svk_correction_bug created.</a> |
Le patch est déposé dans ~/.svk/patch.
Vous pouvez lister vos patchs en faisant :
|
1 2 3 |
<a name="h4.3"> % svk patch --list svk.pod@1: svk_correction_bug@1:</a> |
|
1 |
<a name="h4.3"> % svk patch apply svk_correction_bug</a> |
Répliquer un dépôt local sur un dépôt distant
|
1 2 3 |
<a name="h4.4"> % svk depotmap remote /tmp/remote New depot map saved. Repository /tmp/remote does not exist, create? (y/n)y</a> |
Le dépôt est créé. On peut voir la liste des dépôts gérés par SVK en faisant :
|
1 2 3 4 5 |
<a name="h4.4"> % svk depotmap --list Depot Path ============================================================ // /home/nc/.svk/local /remote/ /tmp/remote</a> |
|
1 |
<a name="h4.4"> % svk list file:///tmp/remote</a> |
svk va vous poser des questions pour créer un miroir local dans le dépôt par défaut //. Répondez par défaut, cela va créer un nouveau chemin de dépôt //mirror/remote.
Synchronisez vos deux dépôts :
|
1 |
<a name="h4.4"> % svk sync //mirror/remote</a> |
Créez le répertoire monprojet qui va accueillir votre projet sur le miroir :
|
1 2 |
<a name="h4.4"> % svk mkdir //mirror/remote/monprojet/ \ -m 'creation du repertoire de monprojet'</a> |
Faites un smerge de votre dépôt local vers votre dépôt :
|
1 2 |
<a name="h4.4"> % svk smerge --baseless --incremental //local/monprojet \ //mirror/remote/monprojet</a> |
|
1 2 |
<a name="h4.4"> % svk smerge --incremental -m "mise a jour" //local/monprojet/ \ //mirror/remote/monprojet/</a> |
-
soit vous faites le
smergevu ci-dessus à la main de temps en temps. -
12<a name="h4.4"> % svk copy -m "creation" //mirror/remote/monprojet/ \//local/monprojet-nouveau</a>
Voila, vous pouvez maintenant faire un
checkoutde //local/monprojet-nouveau et travailler dessus :123456789<a name="h4.4"> % svk checkout //local/monprojet-nouveau% cd monprojet-nouveau% svk pushAuto-merging (0, 13238) /local/monprojet-nouveau to/mirror/remote/monprojet (base /mirror/remote/monprojet:13223).===> Auto-merging (0, 13238) /local/monprojet-nouveau to/mirror/remote/monprojet (base /mirror/remote/monprojet:13223).Merging back to mirror source file:///tmp/remote.Empty merge.</a> -
123<a name="h4.4"> % ls ~/.svk/local/hookspost-commit.tmpl post-revprop-change.tmpl pre-commit.tmplpre-revprop-change.tmpl start-commit.tmpl</a>
Voici le hook utilisé dans le cas présent :
1234<a name="h4.4"> % cat ~/.svk/local/hooks/post-commit#!/bin/shsvk smerge --incremental //local/monprojet //mirror/remote/monprojet</a>Pensez à le rendre exécutable :
1<a name="h4.4"> % chmod +x ~/.svk/local/hooks/post-commit</a>
Métadonnées ou propriétés
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<a name="h4.5"> % svk proplist README % svk propset copyright 'NBC 2007' script/server M script/server % svk propset copyright 'NBC 2007' README M README % svk proplist README Properties on README: copyright % svk propget copyright README NBC 2007 % svk propdel copyright README M README % svk proplist README</a> |
|
1 2 3 4 5 6 |
<a name="h4.5"> % svk diff README Property changes on: README ___________________________________________________________________ Name: copyright +NBC 2007</a> |
Voici un certain nombre de propriétés utiles :
- svn:executable
permet de rendre un fichier exécutable
1% svk propset svn:executable 1 script/*rendra tous les fichiers du répertoire script exécutables suite à une commande
checkoutouupdate. - svn:eol-style
permet de traiter le « problème » des fins de ligne qui sont différentes suivant les systèmes d’exploitation. En utilisant la valeur « native », SVK utilisera automatiquement la fin de ligne normale du système sur lequel vous travaillez au moment de créer un fichier et non celle utilisée par le créateur du fichier :
1% svk propset svn:eol-style native **/*.rbVous pouvez aussi forcer un type de fin de ligne en utilisant les valeurs CRLF, CR ou LF.
- svn:ignore
permet d’ignorer certains répertoires et fichiers qui n’ont pas à être journalisés :
1% svk propset svn:ignore "*" tmp/ignorera tous les fichiers créés dans tmp/
Vous pourrez trouver une liste plus complète des propriétés dans la documentation de Subversion http://svnbook.red-bean.com/. Attention, toutes les propriétés existantes dans Subversion ne sont pas forcément implémentées dans SVK.
Configuration de SVK
|
1 2 |
<a name="h4.6"> [miscellany] global-ignores = *.o *.lo *.la #*# .*.rej *.rej .*~ *~ .#* .DS_Store</a> |
|
1 2 3 4 5 6 7 |
<a name="h4.6"> [miscellany] enable-auto-props = yes [auto-props] *.rb = svn:eol-style=native *.pl = svn:eol-style=native *.png = svn:mime-type=image/png ...</a> |
Éléments de méthode de travail
Voici un diagramme récapitulant les flux des commandes importantes de SVK :
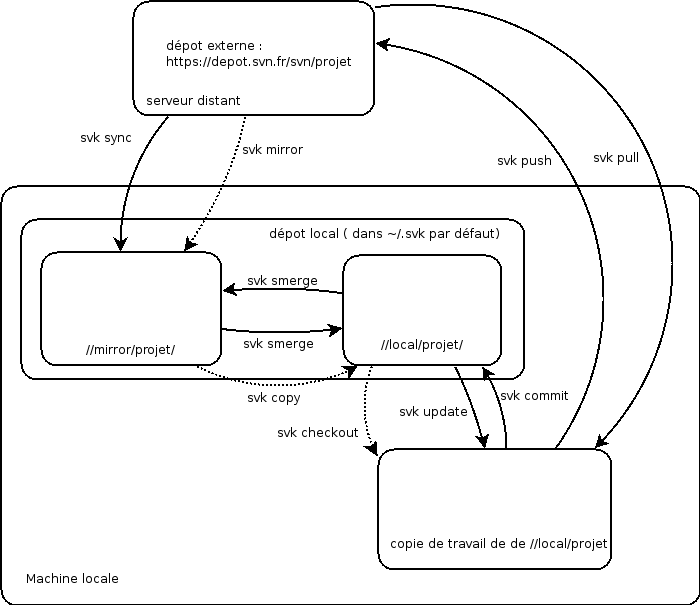
SVK version 2
- les commits interactifs
Sans doute la plus intéressante à première vue, la commande (
svk commit --interactive) vous montre les différentes modifications effectuées et vous permet de sélectionner celles que vous voulez effectivement commiter, les autres restant à l’état de modifications dans votre copie de travail ; - l’amélioration de la sortie des journaux
Vous pouvez maintenant y appliquer des filtres (recherche par exemple) et modifier la sortie (standard, XML, …) ;
- l’apparition des vues
Les vues peuvent être vues comme les vues des bases de données ou comme des liens symboliques unix. Elles permettent de référencer une arborescence sous un autre nom (plus parlant).
Une liste complète des modifications de la version 2 est disponible sur le CPAN : http://search.cpan.org/src/CLKAO/SVK-v2.0.0/CHANGES
Seul inconvénient, mais de taille à mon avis, cette version n’est, sauf erreur, pas encore disponible en paquetage (sauf peut-être pour Mac OS X), vous devrez donc l’installer à la main. À moins d’en avoir besoin et de savoir ce que vous faites, je vous conseille de rester à la version installée par votre système de gestion de paquetages et d’attendre qu’elle soit disponible dans votre système d’exploitation ou distribution préféré. Ceci étant dit, cette nouvelle version fonctionne très bien pour moi depuis quelque temps déjà.
Quelques idées en l’air
-
1<a name="h7"> svk ls svn+ssh://mon.serveur.principal/home/nc/.svk/local/</a>1<a name="h7"> svk pull //mirror/serveurprincipal/</a>
-
pour gérer plus facilement la traduction de documents comme expliqué par le développeur de SVK lui-même : http://www.onlamp.com/pub/a/onlamp/2004/09/09/svk_translation.html.
-
vous pouvez imaginer versionner tout ou partie de votre répertoire personnel sous SVK et faire un miroir de tout cela sur vos différents ordinateurs. Cela permet d’avoir un backup à peu de frais et/ou de synchroniser certains fichiers intéressants (.zshrc, …)
-
il peut servir à un administrateur système pour versionner les fichiers de configuration de ses serveurs avec le gros avantages sur certains autres outils du même type de ne pas avoir besoin d’un répertoire spécial comme CVS ou .svn et de pouvoir importer sur place un répertoire. Imaginez par exemple que sur tous vos serveurs vous fassiez :
1% svk import --to-checkout /etc/ //local/etc-serveur1et qu’ensuite pour poussiez tout cela sur un serveur SVK centralisé grâce à la recette vu plus haut pour répliquer un dépot local sur un dépot distant. Cerise sur le gateau, vous pouvez même le faire sans ouvrir de trou dans votre pare-feu en utilisant les redirections de
SSH.Depuis votre serveur central vous pouvez voir toutes les modifications apportées à vos fichiers de configuration (bonjour ITIL). Vous pouvez comparer la version locale avec la version distante pour vérifier que rien n’a changé (voire automatiser cela et envoyer un mail en cas de changement).
Comme vous le voyez, les possibilités sont larges.
Les liens
-
http://svk.elixus.org/ — La page du projet
-
http://svkbook.elixus.org/ — Le manuel (en cours d’écriture)
-
http://svk.bestpractical.com/ — Le wiki de SVK
-
http://www.redmine.org — rien à voir avec SVK mais c’est un application web de gestion de projets GPL qui mérite vraiment le détour. Simple, de bon gout et pourtant vraiment puissant.